Analyzing and Mitigating Inconsistency in Discrete Speech Tokens for Neural Codec Language Models
Congratulation: Our work is accepted by ACL 2025! Abstract. Building upon advancements in Large Language Models (LLMs), the field of audio processing has seen increased interest in training speech generation tasks with discrete speech token sequences. However, directly discretizing speech by neural audio codecs often results in sequences that fundamentally differ from text sequences. Unlike text, where text token sequences are deterministic, discrete speech tokens can exhibit significant variability based on contextual factors, while still producing perceptually identical audio segments. We refer to this phenomenon as Discrete Representation Inconsistency (DRI). This inconsistency can lead to a single speech segment being represented by multiple divergent sequences, which creates confusion in neural codec language models and results in poor generated speech. In this paper, we quantitatively analyze the DRI phenomenon within popular speech tokenizers such as EnCodec. Our approach effectively mitigates the DRI phenomenon of the neural audio codec. Furthermore, extensive experiments on the neural codec language model over LibriTTS and large-scale MLS dataset (44,000 hours) demonstrate the effectiveness and generality of our method.
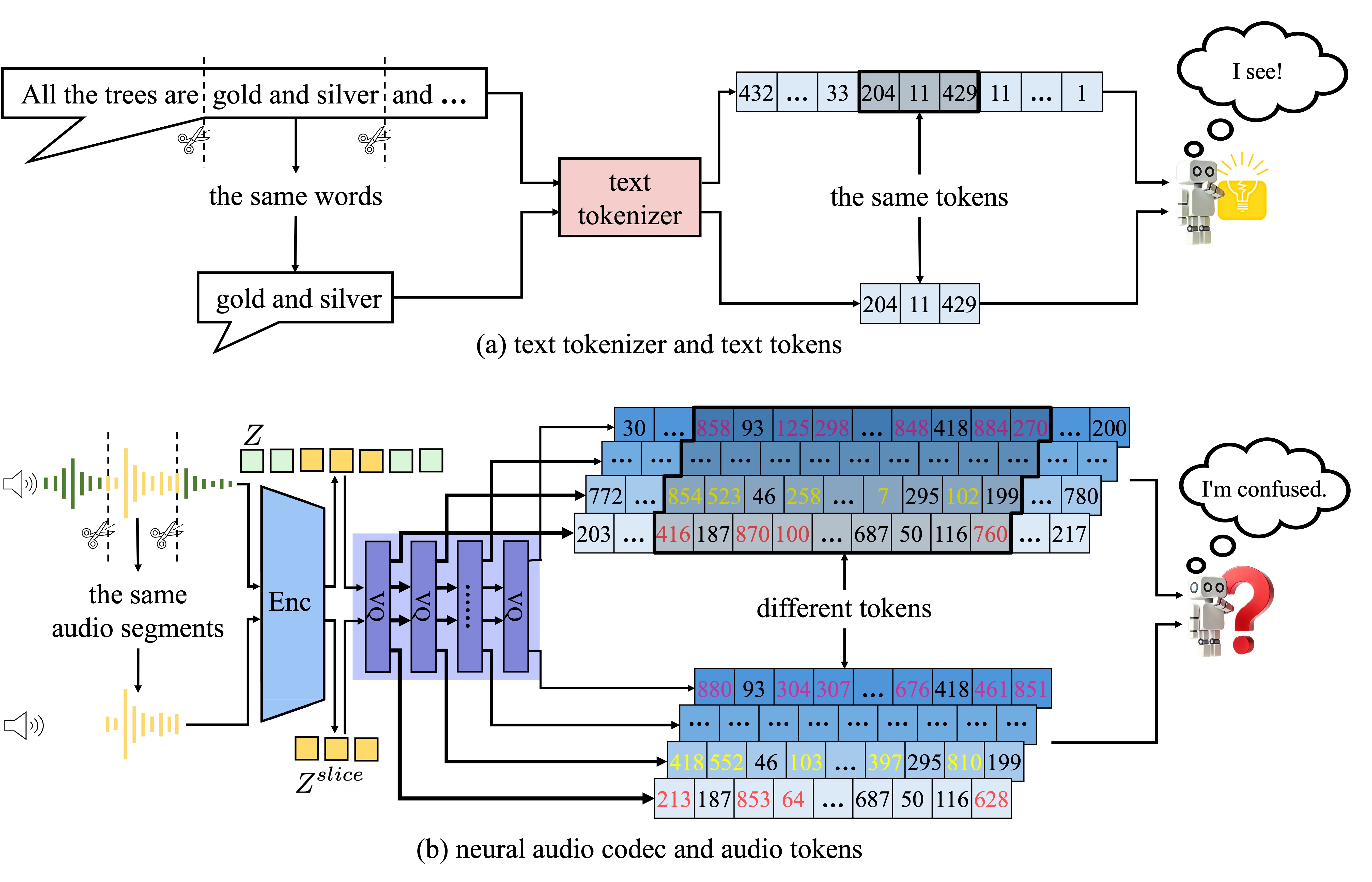
Figure: The Illustration of Discrete Representation Inconsistency (DRI)
phenomenon. Subfigure (a) shows
that text, whether it includes contextual information or not, can be encoded by the text tokenizer into
the same text tokens. In contrast, Subfigure (b) illustrates that audio, with or without contextual
information, is encoded by the audio tokenizer into different speech tokens. The DRI phenomenon within the
audio tokenizer poses a many-to-one mapping problem, and the complexity of this many-to-one mapping raises
the uncertainty for neural codec language models in predicting the next token.
2 Analysis on DRI Phenomenon within Neural Audio Codecs
To analyze the DRI phenomenon, we use neural audio codecs as audio tokenizers to quantize both the entire audio
and an audio segment within that audio, and then compare the results of their corresponding discrete audio token
sequences. As you can hear, these two audio segments are exactly identical with the only difference being whether
there is context, but the discrete audio token sequences are very different, which raises uncertainty for neural
codec language models in predicting the next token.
Ground Truth
Transcript
I believe, Charlie, he recommenced suddenly, there is not such an
unnatural family on record as ours; is there?
We demonstrate speech reconstruction results of popular neural audio codecs (e.g., EnCodec) and the codec training
with consistency constraint (denoted as Ours).
Neural Audio Codec
Samples
sample1
sample2
sample3
sample4
Ground Truth
Transcript
This I took for a sign that he had himself something to produce and that we should only have to
wait.
She looked at his heavy shoulders and big, determined head, thrust forward like a catapult in leash.
Do you suppose that god for the sake of a few lutheran heretics would disown his entire church?
You must see, lieutenant, I should think, that we are not so near the coast of algeria as you
imagined.
Ours
EnCodec
HiFiCodec
SpeechTokenizer
DAC
FunCodec
4 Speech Generation Results
We demonstrate zero-shot text-to-speech (TTS) results of neural codec language models, a representative application of speech generation. The neural codec language models are
based on popular neural audio codecs (e.g., EnCodec) and the codec training with consistency consttraint
(denoted as Ours). The subscripts of the
neural codec language models (e.g., 330M, 44Kh) denote the model size and training data scale.
Neural Audio Codec
Neural Codec Language Model
Samples
sample1
sample2
sample3
sample4
Ground Truth
Text
And the lectures, and the dissecting rooms, has thee thought of the dissecting rooms?
Infirmities induced by over indulgence are among some peoples freely recognised as manly attributes.
He was particularly attentive to the behavior of their preachers, on whom all depended.
He reminds them of the time when he opposed peter to his face and reproved the chief of the apostles.
Target Audio
Reference
Reference Text
He would say good night, but not good bye .
but that does not remain the sole purpose of their consumption .
The parliament and the scots laid their proposals before the king.
Humble man that he was, he will not now take a back seat.